: Все продукты ABBYY так или иначе используют элементы ИИ")
Друзья, мы продолжаем публикацию на нашем портале материалов на актуальную сегодня тему использования технологий искусственного интеллекта и машинного обучения для самых разных задач как в бизнесе, так и в науке.
Сегодня мы предлагаем вашему вниманию интервью с генеральным директором компании ABBYY Россия Дмитрием Шушкиным.
Robogeek.ru: Добрый день, Дмитрий! Расскажите немного о себе. Как давно и кем Вы работаете в компании, чем занимаетесь?
Дмитрий Шушкин: Здравствуйте! В ABBYY я уже около 15 лет, работать начал в 2004 году как менеджер по корпоративным проектам, в 2010 году получил должность директора этого направления. За это время я реализовал ряд крупных и уникальных для компании проектов в знаковых заказчиках: РЖД, Федеральной службе по финансовому мониторингу, Альфа-Банке и других. С 2017 года возглавляю офис ABBYY Россия, отвечаю за деятельность на территории РФ и стран СНГ.
Robogeek.ru: Мало можно встретить людей, которым надо представлять Вашу компанию, и еще меньше тех, кому не знакомы Ваши продукты. Но все же давайте коротко поговорим о некоторых направлениях деятельности ABBYY.
Дмитрий Шушкин: ABBYY – мировой разработчик решений в области интеллектуальной обработки информации для задач бизнеса. Сегодня 90% наших доходов приносят проекты для корпоративных заказчиков. Технологии ABBYY применяются на всех этапах работы с информацией. Это распознавание и извлечение данных, определение типа документов, ввод в информационные системы, анализ содержания и поиск. Мы создаем технологии искусственного интеллекта, которые позволяют на качественно новом уровне обрабатывать большие объемы текстовых данных и эффективно работать с ними. В целом можно сказать, что решения ABBYY делают разрозненную информацию из множества источников доступной для обработки, поиска, анализа и применения в бизнесе на качественно новом уровне. Это направление называется Content Intelligence.
Наша компания начинала с технологий распознавания, затем мы стали разрабатывать системы потокового ввода данных. Последние годы мы активно развиваем технологии анализа и понимания текстов на естественном языке (natural language proccessing, NLP) и уже несколько лет успешно выводим решения с применением NLP на рынок. Мы видим, что это перспективное направление бизнеса. Аналитики Tractica прогнозируют, что к 2025 году мировой рынок NLP достигнет $22,3 млрд. Благодаря этим технологиям компании могут автоматически получать данные не только из структурированных документов, таких как счета и квитанции, но и из неструктурированных. К ним относятся договоры, контракты, приложения, письма, новости, посты на сайтах и в соцсетях и т. д. NLP значительно расширяет возможности компаний в работе с документами: позволяет быстрее обслуживать клиентов, создавать новые продукты, анализировать финансовые показатели, отзывы пользователей и так далее.
Robogeek.ru: Насколько нам известно, в ряде продуктов ABBYY используются технологии машинного обучения, искусственного интеллекта. В какой момент компания обратила внимание на эти направления? Что эти технологии привнесли в Ваши продукты?
Дмитрий Шушкин: Мы больше 20 лет занимаемся разработками в области искусственного интеллекта и машинного обучения, ещё со времен, когда компания только начинала выход на международный рынок. Все продукты ABBYY так или иначе используют элементы ИИ. В универсальной программе для работы с бумажными и PDF-документами ABBYY FineReader технологии компьютерного зрения используются для структурного анализа, распознавания символов и превращения изображений в редактируемые текстовые форматы.
ABBYY FlexiCapture – платформа для интеллектуальной обработки информации, которая автоматически классифицирует и извлекает данные из любых документов и отправляет их в корпоративные системы. В решении используются технологии машинного обучения и свёрточных нейронных сетей, которые позволяют гибко и удобно управлять всей информацией в едином потоке. Кроме того, мы недавно дополнили платформу функциональными модулями NLP, чтобы платформа могла работать и с неструктурированными документами.
В решении ABBYY Intelligent Search также используются методы NLP. Они позволяют выполнять ряд задач: искать информацию независимо от того, на каком языке сделан запрос, выявлять в текстах объекты, факты и связи между ними, определять тип документа по его внешнему виду и содержанию, а в конечном счёте – искать по смыслу, а не по словам. Это даёт возможность использовать наши решения во многих бизнес-процессах: например, для обработки кредитного досье, оценки корпоративных рисков, автоматизации клиентской поддержки, в закупочной деятельности и многих других.
Robogeek.ru: Все разработки ведутся внутри компании или совместно с кем-то?
Дмитрий Шушкин: Продукты ABBYY – это наши собственные разработки. Мы инвестируем значительные средства в R&D: в среднем около 25% ежегодных доходов. В департаменте R&D ABBYY есть два основных направления: NLP и OCR. Сотрудники занимаются исследованиями в области распознавания текстов и обработки естественного языка для наших заказчиков. Часто им приходится иметь дело с задачами, для которых ещё никто в мире не создал готовых решений.
Технологии и решения ABBYY лицензируют крупнейшие международные ИТ-компании, вендоры решений для потокового ввода документов, производители сканеров и МФУ-устройств. Среди них Fujitsu, Epson, Hewlett Packard Enterprise, RICOH, Xerox и многие другие. Кроме того, у ABBYY в мире большая партнёрская сеть: только в России мы сотрудничаем с более чем 170 компаниями, в том числе с разработчиками технологий. Это, например, все крупнейшие производители систем по защите от утечек данных (Data Leakage Protection, DLP). Технологии ABBYY в составе DLP-систем позволяют предотвращать утечки информации, переданной в виде изображений: сканов, фотографий и скриншотов конфиденциальных документов. Разработчики систем электронного документооборота, такие как «Логика бизнеса», «ЛАНИТ», ЭОС, используют наши решения, чтобы распознавать данные, сравнивать разные версии документов и определять их тип. Ещё один наш партнер - компания VisionLabs, разработчик технологий по распознаванию лиц. Вместе мы создали решение для удаленной идентификации документов, которое сравнивает фотографию в паспорте с лицом пользователя и в реальном времени извлекает данные из документа для дальнейшей обработки. Подобные решения используют для удаленной оплаты услуг, покупки билетов, регистрации SIM-карт. Мы также активно сотрудничаем с разработчиками решений по роботизации бизнес-процессов (Robotic process automation, RPA) и создали ряд готовых коннекторов к этим системам. Наши технологии дополняют возможности программных роботов: с решениями ABBYY они могут не только перемещать файлы и копировать информацию, но и полноценно работать с содержанием любых, в том числе сложных, документов.
Robogeek.ru: Многие люди по-разному воспринимают понятие «искусственный интеллект». Расскажите, что вкладывают в это понятие в ABBYY?
Дмитрий Шушкин: Под искусственным интеллектом мы понимаем ряд алгоритмов и программных систем, которые могут решать некоторые задачи так, как это делал бы на их месте человек. Например, обучаться на основе информации или заданных правил, собирать данные, извлекать их из различных источников и так далее. ИИ применяется для создания экспертных систем, обработки данных на естественном языке, распознавания речи и машинного зрения.
Robogeek.ru: Могли бы Вы поделиться своим видением, как ИИ уже трансформировал современный бизнес и, предположительно, трансформирует в будущем?
Дмитрий Шушкин: Я считаю, что ИИ уже значительно изменил бизнес-процессы во многих отраслях, в том числе и в России. В первую очередь, это повлияло на клиентское обслуживание, потому что потребитель нынче весьма требователен, плюс за счёт доступности технологий он помолодел. Приведу в пример банки. Раньше для того, чтобы оплатить счет, пользователю нужно было перепечатывать длинные реквизиты в личном кабинете. Сегодня во многих банках это делает ИИ в мобильном приложении. К примеру, нашу технологию ABBYY FineReader Engine используют ряд банков, включая Сбербанк, Альфа-банк, Модульбанк, «Тинькофф банк» и «Точку». Многие финансовые учреждения начали применять ИИ для удалённой идентификации при регистрации и оплате различных услуг. Другой пример – открытие счета для юридического лица. Во многих банках комплекты документов от предпринимателей не так давно неделями обрабатывали целые отделы сотрудников. Сейчас благодаря ИИ на это уходит всего несколько часов. Например, такое решение использует ВТБ: они автоматически извлекают данные из договора, устава компании, паспорта, ИНН и других документов. В результате они обслуживают на 25% больше представителей малого и среднего бизнеса, не увеличивая штат сотрудников, а значит, у них намного меньше очередей и больше довольных клиентов. Сбербанк использует технологии ABBYY для мониторинга новостей о более чем 1000 контрагентах в реальном времени. ИИ точно определяет смысл текста и выявляет в инфополе упоминания рисковых факторов, таких как изменения в структуре собственности, нарушение условий сделок. В результате сотрудники отслеживают на порядок больше сообщений в месяц.
Ещё совсем недавно у розничных магазинов не было возможности создать для покупателя индивидуальные скидки и предложения. Всем подряд рассылали информацию о новом сорте чая, распродаже хлопьев и акции на детский шампунь. Сейчас благодаря ИИ пользователи получают предложения с учетом того, что они покупали раньше, какие отзывы оставляли о товарах в интернете или социальных сетях, какие запросы делали в поисковой системе. Это помогает намного лучше понимать потребителя и увеличивать продажи. Например, в России похожими решениями пользуются «Перекресток», «М.Видео», «Эльдорадо», интернет-магазин Ozon.ru, Вкусвилл.
Крупные энергетические и промышленные корпорации начали внедрять ИИ для интеллектуального поиска по внутренним источникам данных. Такие решения позволят бизнесу в десятки раз быстрее разрабатывать, производить и выводить новые продукты на рынок. К примеру, в России такую технологию пилотирует НПО «Энергомаш», входящий в корпорацию Роскосмос.
Robogeek.ru: И несколько вопросов по платформе для интеллектуальной обработки информации ABBYY FlexiCapture. Расскажите, каким образом эта платформа устроена и работает? Прежде всего, распознавание текста, классификация с применением ИИ и т. д.
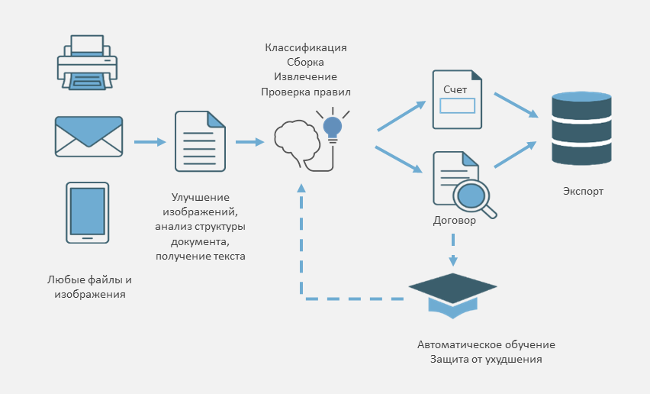
Дмитрий Шушкин: Всё довольно просто. Сначала вам нужно загрузить файлы на платформу. Это может быть электронный, бумажный документ, его скан или фотография, отдельные страницы или целые комплекты документов. Для этой и последующих процедур платформа предлагает специальные удобные интерфейсы взаимодействия, включая мобильные. Дальше решение распознает тексты, на данный момент доступно около 200 языков. Параллельно запускается каскадная классификация: изображение – текст – смысл. Благодаря ИИ можно автоматически разделить документы по типам – например, когда нужно быстро найти в общем комплекте паспорт или анкету клиента просто по внешнему виду документа, или по пользовательским категориям – скажем, если нужно отделить счета-фактуры одной компании от другой. С помощью свёрточных нейронных сетей технология сама учится определять тип документа по всем указанным параметрам.
После классификации ABBYY FlexiCapture извлекает нужные данные и запускает автоматические проверки: приводит информацию в единый структурированный вид, сверяет с данными в базе, между страницами документа, между документами, проверяет комплектность и так далее. На следующем этапе сотрудник проверяет, корректно ли распознаны и извлечены данные, в которых программа не до конца уверена сама. Если всё верно, они поступают в целевую систему. Это может быть ECM, ERP, BPM или другое решение – в зависимости от задач компании. Несколько лет назад мы начали сотрудничать и с производителями RPA-решений – эти вендоры автоматизируют бизнес-процессы с помощью программных роботов. В случае с RPA структурированные и проверенные данные поступают в распоряжение робота, который уже определяет, что с ними нужно делать дальше и в каком бизнес-процессе: скопировать в какую-то таблицу, добавить в папку или, например, отправить автоматическое уведомление в тот или иной отдел.
Robogeek.ru: В каких отраслях, на Ваш взгляд, эта разработка будет более всего востребована?
Дмитрий Шушкин: ABBYY FlexiCapture – универсальная платформа для интеллектуальной обработки информации, которая уже много лет широко востребована почти во всех отраслях. Как на российском, так и на мировом рынках мы являемся признанным лидером в решениях этого класса. По результатам последнего исследования IDC в России, рыночная доля ABBYY в области потокового ввода данных составляет более 60%. Наиболее крупные заказчики – это банки, нефтегазовые, энергетические компании, ритейл, телеком и государственный сектор. В начале января 2019 года Research and Markets назвала ABBYY в числе главных компаний на мировом рынке решений для обработки данных из документов.
В банках ABBYY FlexiCapture помогает открывать счета для физических и юридических лиц, обрабатывать кредитные заявки, извлекать данные из платежных документов, оценивать заёмщиков и партнёров. В энергетике платформа позволяет обрабатывать первичные документы и проводить транзакции, извлекать данные из договоров и заявок на техническое присоединение, создавать электронный архив технической, кадровой и другой документации. В нефтегазовой отрасли и промышленности ABBYY FlexiCapture используют для обработки бухгалтерской и организационно-распорядительной документации. В государственных организациях платформу применяют для создания архива, а также для обработки и подготовки ответов на обращения граждан.
Robogeek.ru: Каким образом планируете развивать данный продукт в будущем? Может быть уже есть идеи новых разработок на основе ИИ и МО?
Дмитрий Шушкин: 11 января мы обновили ABBYY FlexiCapture: дополнили платформу технологиями обработки естественного языка. Раньше решение без связки с другими нашими продуктами обрабатывало только структурированные и слабоструктурированные документы. Благодаря включению модулей NLP в платформу она стала универсальным инструментом для работы с любыми документами, даже такими «сложными», как договоры, уставы, тексты новостей и любые другие данные. Решение может определить тип таких документов и получить из них нужную информацию, выстроить и извлечь в удобном формате все смысловые связи. Например, обязательства сторон в договоре, риск-факторы в новостях о контрагентах, опыт работы и навыки из резюме сотрудника, составленного в свободной форме.
Кроме того, мы усовершенствовали технологии, отвечающие за предварительную обработку документов. Они позволяют извлекать данные даже из изображений низкого качества со сложным фоном, печатями, водяными знаками, голограммами или исправлениями ручкой. Новая ABBYY FlexiCapture автоматически обрезает скан или фотографию по границам документа, выравнивает фон, повышает резкость текста и удаляет ненужные элементы. Если система понимает, что качественно распознать данные не удастся, то сразу же информирует пользователя о необходимости сделать еще одну фотографию или скан. Это помогает снизить нагрузку на сотрудников компании, заранее исключив изображения, не пригодные для обработки.
Robogeek.ru: Дмитрий, спасибо Вам большое за ответы! Желаем дальнейшего активного развития и новых интересных проектов и разработок.
Комментарии
(0) Добавить комментарий