")
Живя в динамичном физическом мире мы не придаем значения тому, как легко мы воспринимаем окружающую действительность. При минимальном уровне напряжении мысли, мы можем понять, как изменится видимая ситуация и как взаимодействуют при этом объекты.
Но то, что нам кажется естественным, по-прежнему является огромной проблемой для машин. При безграничном количестве способов перемещения объектов, прогнозирование развития событий для машин может оказаться затруднительным.
Недавно исследователи из Массачусетского технологического института (МИТ) еще на один шаг продвинулись в разработке алгоритма глубокого обучения, способном по неподвижным изображениям создавать короткие видеоролики, которые моделируют будущее состояние этих объектов.
Обученный на двух миллионах примеров алгоритм генерировал видео, которые казались людям на 20 % более реалистичными, чем те что создавал алгоритм в базовой модели.
Необходимо уточнить, что на данный момент разрешение видео все еще остается относительно низким, а длительность всего 1-1,5 секунд. Но команда надеется, что будущие версии могут найти самые разнообразные применения, от усовершенствованных алгоритмов безопасности до предсказания опасности в системах автономного вождения.
Согласно утверждению первого автора этой идеи Карла Вондричка, алгоритм может также помочь машинам распознавать деятельность людей без дорогостоящих аннотаций от человека. «Эти видео показывают нам, что компьютеры «думают» о том, что может случиться в сцене. Если вы можете предсказать будущее, то должны понимать настоящее», - говорит Вондричек.
Эта работа исследователей из МИТ будет представлена на следующей неделе в Барселоне на конференции Системы нейронной обработки информации.
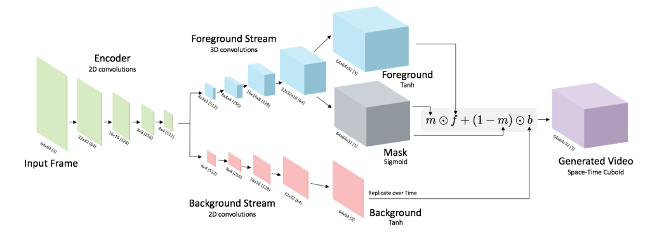
Как это работает?
Ранее несколько исследователей решали подобные задачи в области компьютерного зрения, в том числе профессор MIT Билл Фриман, чья новая работа также позволяет создавать будущие кадры на сцене. Но там, где его модель фокусируется на экстраполяции видео в будущее, новая модель может также генерировать совершенно новые видео, которых не было раньше.
Предыдущие системы создавали сцены кадр за кадром, что накапливает целый ряд ошибок. В противоположность этому новый метод создает всю сцену сразу. Команда использовала метод глубокого обучения, называемый «состязательное обучение», который включает обучение двух конкурирующих нейронных сетей. Одна сеть генерирует видео, а другая ищет различия между реальным и сгенерированным видео. Со временем генератор учится обманывать распознавателя. И сможет создавать видеоролики, напоминающие сцены с пляжей, на вокзалах, больницах и полях для гольфа. Например, модель пляжа воспроизводит набегающие волны, а другая модель идущих по траве на поле для гольфа людей.
Эти типы моделей не ограничиваются предсказанием будущего. Генерируемое видео можно использовать для добавления анимации неподвижных изображений, например, живая газета из серии книг о Гарри Поттере.
Комментарии
(0) Добавить комментарий